

As the use of Kubernetes grows significantly in production environments, backing up the configuration of these clusters is becoming ever more critical. In previous blogs we have talked about the difference between stateful and stateless workloads, but this blog is focusing on backing up the cluster config, not the workloads.
When running a Kubernetes cluster in an environment the Kubernetes Master node contains all the configuration data including items like worker nodes, application configurations, network settings and more. This data is critical to restore in the event of a failure of the master node.
For us to understand what we need to backup, first we need to understand what components Kubernetes needs to operate.
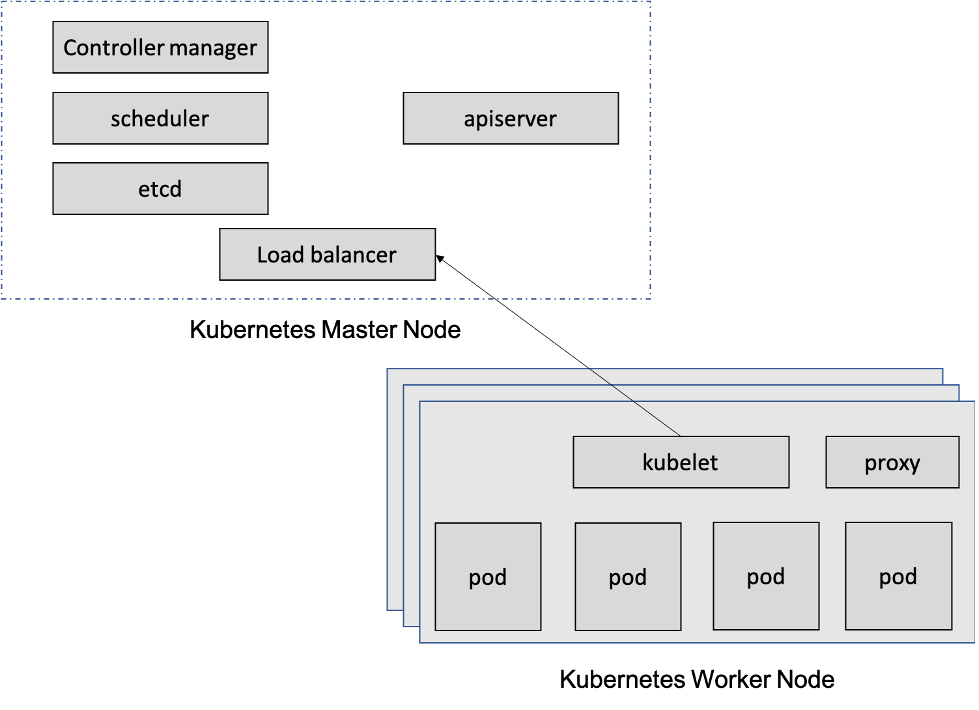
In Kubernetes the etcd is one of the key components. etcd is used as Kubernetes’ backing store. All cluster data is stored here. Etcd is an open-source key value store and is used for persistent storage of all Kubernetes objects like deployment and pod information. The etcd can only be run on a master node. This component is critical for backing up Kubernetes configurations.
Another key component are the certificates. By backing these up we can easily restore a master node. Without them we would need to recreate the cluster from scratch.
We can back up all the key Kubernetes master node components using a simple script. I got the basics of the script from this site (https://elastisys.com/2018/12/10/backup-kubernetes-how-and-why/)
#K8S backup script
# David Hill 2019
# Backup certificates
sudo cp -r /etc/kubernetes/pki backup/
# Make etcd snapshot
sudo docker run –rm -v $(pwd)/backup:/backup \
–network host \
-v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \
–env ETCDCTL_API=3 \
k8s.gcr.io/etcd-amd64:3.2.18 \
etcdctl –endpoints=https://127.0.0.1:2379 \
–cacert=/etc/kubernetes/pki/etcd/ca.crt \
–cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
–key=/etc/kubernetes/pki/etcd/healthcheck-client.key \
snapshot save /backup/etcd-snapshot-latest.db
The script above does two things. 1) It copies all the certificates and 2) it creates a snapshot of the etcd keystore. These are all saved in a directory called backup.
After running the script, we have a number of files in the backup directory. These include certificates, snapshots and keys required for Kubernetes to run.
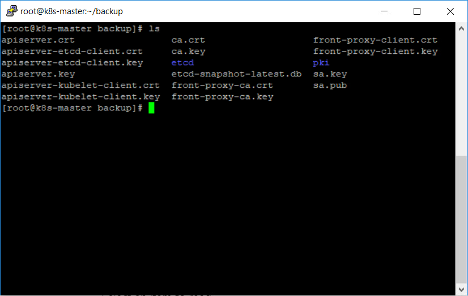
Great! We now have a backup of the critical Kubernetes Master node configuration. The issue is now, this data is all stored locally. What happens if we lose the node completely? This is where Veeam comes in. By using the Veeam agent for Linux we can easily backup this directory and store in a different location. By using the agent we can protect this critical data but also manage and store that data in multiple locations, like a scale out backup repository and the cloud tier leveraging object storage.
Veeam Agent for Linux
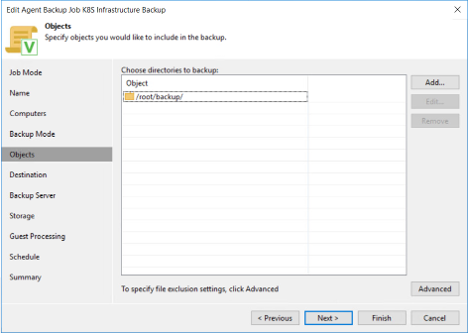
When configuring the backup job, we only want to back up the directory where the Kubernetes configuration data is stored. By running the script above, we stored all that data in /root/backup. That is the directory we are going to back up in this example.
Walking through the backup job for our master node, two options we must select are File Level Backup and we must specify the directory to backup:
Once the job is run, we can open up the backup and check all the files we requested to be backed up were included.
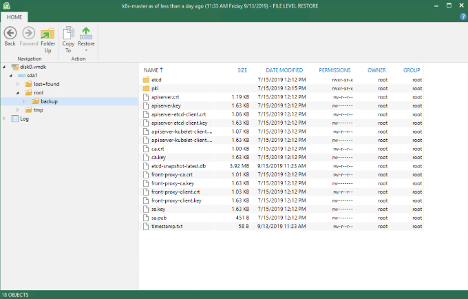
We now have a successful back up of our Kubernetes Master Node configuration. We can offload this backup to an object storage repository for offsite backup storage.
No comments yet.